本文最后更新于:5 years ago
网络爬虫
查看源代码
按F12查看network监听请求(抓包)
解密
提取HTML中所有URL链接
思路:1)搜索到所有标签2)解析<a>标签格式,提取href后的链接内容。
正则表达式
基础
1.\w 字母、数字、下划线
2.\W 除字母、数字、下划线
3.\d 十进制数字
4.\D 除十进制数字
5.\s 空白字符
6.\S 除空白字符
7.[abc] 代表原子表只选择其中一个abc
8.[ ^abc ] 代表非abc的一个
元字符
- 点 表示除换行符任意字符
- ^ 匹配开始位置
- $ 匹配结束位置
- ‘*’ 匹配0\1\多次
- ? 0\1次
- ‘+’ 1\多次
- {n} 恰好n次
- {n,} 至少n次
- {n,m} 至少n次,至多m次
- | 表示或
- () 模式单元
模式修政符
- I 匹配时忽略大小写
- M 多行匹配
- L 本地化识别匹配
- U Unicode
- S 让. 匹配包括换行符
应用:
string="Python"
pat="pyt"
rst=re. search(pat, string, re.)
print(rst)贪婪模式与懒惰模式
应用:
#贪婪模式与懒惰模式
string="poythonyhjskjsa
pat1="p.*y"#贪婪模式
pat2="p.*?y"#懒惰模式python 中正则表达式函数
re.match() #与search用法一致,不过是从头匹配
re.search() #第一个变量放正则表达式,第二个放内容
re.sub()
全局匹配
#全局匹配格式re. compile(正则表达式). findall(数据) rst=re. compile(. findall(string)
常见正则实例
- 匹配网址:”[a-zA-Z]+://[ ^\s]*[.com|.cn]”
- 匹配电话号码:”\d{4}-\d{7} |\d{3}-\d{8} “
简单爬虫urllib编写
import urllib.request
import re #正则库
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = "正则表达式"
result = re.compile(pat).findall(data) #列表
print(result)
import urllib. request
#ur retrieve(网址,本地文件存储地址)直接下载网页到本地
ur ll ib. request. ur Iretrieve ("http: //www. baidu. com", "d: \" )
urIlib. request. ur lcleanup
#看网页相应的简介信息info
file=urllib. request. ur lopen ("https: //read. douban. com/pr..")
print(file. infoO)
#返回网页爬取的状态码getcode
print(file. getcode()
#获取当前访问的网页的url, geturI0
print(file. geturl0)
post请求实战
import urllib. request
import urllib. parse
postur l="http: //www. igianyue. com/mypost/"
postdata=ur llib. parse. ur lencode (
"name": "ceo@txk7. com"
"pass": "kjsahg jkashg",
]) encode("utf-8")
#进行post,就需要使用 ur Ilib. reqestRequest下面的(真实post地址,post数据
req=ur llib. request. Request (postur, postdata)
rst=ur ll ib. request. ur lopen(reg. read. decode ("utf-8")
open(":\\我的教学\Python\韬云教育-讯 Python爬虫pw")
requests 库
import requests
# 添加 headers
headers = {
"User-Agent":..
}
response = request.get(url,headers=headers)
demo = response.text #网站源代码
response.content #二进制文件BeautifulSoup 库
1.使用方式
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>data</p>",'html.parser')
soup.prettify() #可以使源代码清晰
2.基本元素
| Tag | 最基本的信息组织单元,分别用<>和</>表明开头和结尾 |
|---|---|
| Name | 标签的名字, … 的名字是‘p’,格式: |
| Attributes | 标签的属性,字典形式组织,格式: |
| NabigableString | 标签内非属性字符串,<>…</>中字符串,格式: |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
3.标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的上一个平行节点标签 |
4.获取href
import requests
# 添加 headers
headers = {
"User-Agent":..
}
response = request.get(url,headers=headers)
demo = response.text #网站源代码
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))find_all相关方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,字符串类型,同.find_all()参数 |
Scrapy 框架解析
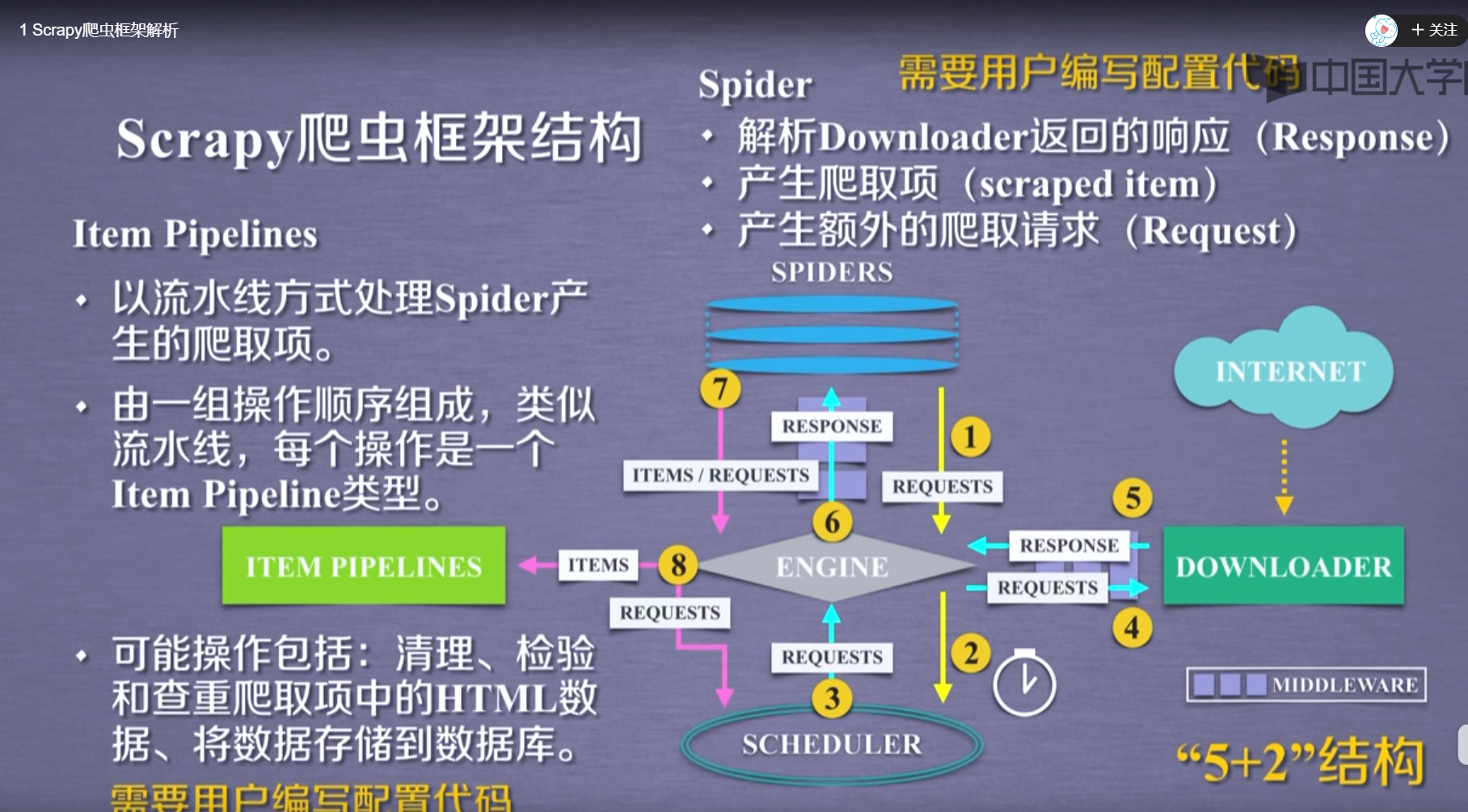
| requests | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
Scrapy 常用命令
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy settings[options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命 | scrapy令行 shellurl |
Scrapy使用步骤
1.选择一个文件夹写项目 输入命令 scrapy startproject 项目名称
2.输入命令 scrapy genspider py名称 域名
3.再 py名称 中配置爬虫
4.输入命令 scrapy crawl py名称 运行爬虫
request 类

respond 类

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!